(这是第一篇开篇,成长之路序列会包含多篇,笔者作为这个平台的架构兼技术经理,充分讲述其中的迭代心酸之路以及中间遇到的问题和解决方案)
声明:文章不涉及公司内部技术资料的外泄,涉及的图片都是重画的简易架构图,主要通过架构的演进,讲述分享技术的迭代之路和过程
苏宁人工智能研发中心成立了于2018年,从2018年下半年开始在规划一个类似京东玲珑和阿里鹿班的一个Banner图的合成平台项目,初期产品设计的是一个sass化的产品,可以对内也可以对外服务,初期规划时,只有如下几个模块。
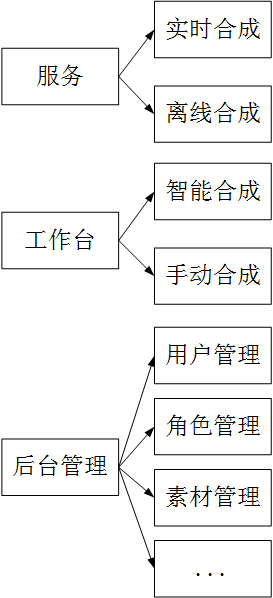
1、 服务:主要是对外提供统一的restful api服务,服务包括离线服务和实时服务。
2、 工作台:指的是一个用户操作合成banner界面,供用户做操作,在鹿班和玲珑中都有。
智能合成,指的是用户可以选择风格标签后,然后平台依靠人工智能自动生成banner图。
手动合成:指的是人可以手工干预合成,比如可以自己选择素材和上传素材(比如banner图的背景,装饰图等)
3、 后台管理指的一个供管理用的界面。
由于一期在规划时,先实现工作台和后台管理两部分,服务一开始不实现,所以初期架构设计如下:
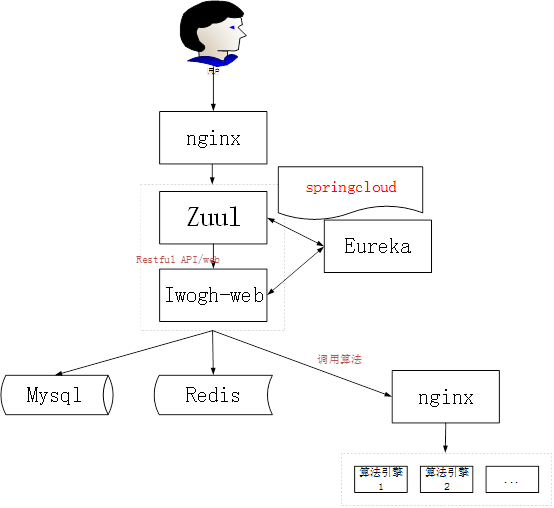
设计的思路如下:
1、 考虑到系统的高可拓展性以及未来平台可能会增加很多其它的服务,并且可能会朝着智能创意来发展,所以在web 框架选型时,我这边选是springcloud+springboot。虽然一开始模块很少,使用springcloud会有点大材小用,但是这个是一个长期不断迭代的项目,所以系统的扩展性在前期一定要先准备好。
2、 由于服务一开始我们并不实现,所以我们其实只有一个模块,就是iwogh-web这个模块。
3、 我们所有的请求还是使用springcloud中的Zuul模块来做理由控制。Eureka来负责服务注册中心。
4、 数据库使用的Mysql数据库,因为一开始数据并不大,关心型的mysql可以满足要求,并不需要一开始就去考虑大数据的方案。
5、 由于算法基本都是python来实现的,所以我们会把python实现的算法包装一个http的服务,包装的时候我们开始选择的是python中的flask框架。
6、 算法的集群实现,我们使用的是nginx来做反向代理转发,一个nginx集群,可以控制很多个不同的算法集群(比如每个不同类型的算法构建一个集群),因为我们可以利用nginx中的location
location的语法:
location [=|~|~*|^~] patt { } //中括号中为修饰符,可以不写任何参数,此时称为一般匹配,也可以写参数
因此,大类型可以分为三种:
location = patt {} [精准匹配]
location patt{} [普通匹配]
location ~ patt{} [正则匹配]
server {
listen 80;
server_name localhost;
location =/text.html { #精准匹配,浏览器输入IP地址/text.html,定位到服务器/var/www/html/text.html文件
root /var/www/html;
index text.html;
}
location / { #普通匹配,浏览器输入IP地址,定位到服务器/usr/local/nginx/html/default.html文件
root html;
index default.html;
}
location ~ image { #正则匹配,浏览器输入IP/image..地址会被命中,定位到/var/www/image/index.html
root /var/www/image;
index index.html;
}
}
当然还有一种思路,就是通过sidecar组件,把算法服务也注册到springcloud中作为一个服务,然后调用算法服务采用spingcloud内部服务的方式来实现。
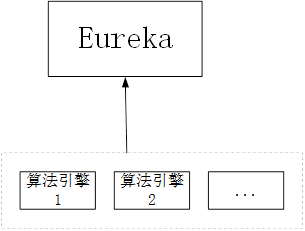
不过最终经过一些考虑,否决了这种想法,
1) 、算法更偏底层,不太适合在应用层的服务中管理,在架构设计时,本来也会给算法设计一层算法工程化服务层,结构大致会这样,算法服务只专注于算法的处理,不会涉及任何的处理逻辑。
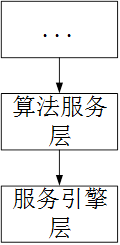
2) 、算法一般是python来实现的,所以工程化的封装一般也是会使用python来包装服务,纳入到以java为主的springcloud服务中来管理,在持续集成发布时,不是非常方便管理。
1、 redis主要用来做分布式的会话session,而且我们还使用session做了另一个设计,由于banner合成时一次是批量合成5张图出来,但是算法底层由于是深度机器学习框架,所以算法处理的速度并不会很快,如果用户在工作台中等待5张图全部合成完,用户的体验会很差,因为等待的时间会很长,所以我们采用了轮询 按照一张一张来加载,并不是等5张banner图全部出来后再一次加载出来,而是出来一张就加载一张。
如下图,在第一步调用算法服务处理完后,生成了banner图后会先存入到图片存储中,然后写入时,会往redis和mysql中同时写入,redis中会有一定的实效时间,因为用户有不可能会在页面一直等,总归是会超时的,实效时间一般设定在了5-10分钟左右。此时页面会轮询的按照requestId+图片序号来获取banner图(每一个请求都会有一个请求的requestId,由于一次是5张图,所以图片是有序号的,可以轮询的获取),轮询获取时,就接口的API服务就可以直接去查询redis了,因为这样查询速度很快,用户体验会更好,图片就会类似实时查询一样,频繁的查询也不影响性能。其实你如果看过鹿班的话,你也会看到,他们的结果图也是分批出来,不是一次出来全部。

在第一轮上线后,由于用户使用体验还可以,给了更多的时间来做第二轮的产品迭代,所以到第二轮迭代时,我们为了支撑服务和其他更多的需求,对架构做了比较大的调整。
在第二轮迭代时,架构图就变成了这样

1、 我们需要支撑接口API服务了,包括实时服务,离线服务,供其他的业务来调用使用。初期API主要分这几种情况
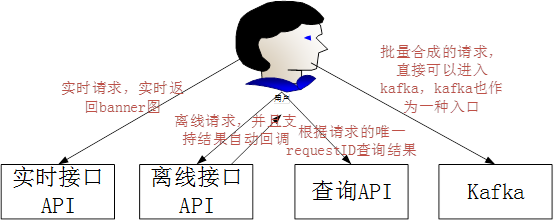
接口API的设计主要包括这几点
1)、客户端每次请求需要带入一个时间戳,服务端会校验这个时间戳,超过一定时间范围内的请求,服务端作为无效的请求自动丢弃,也可以避免接口服务被机器人进行攻击。
2)、每个请求需要带入一个Appid,这个Appid由平台自动分配。
3)、每个请求需要用一个秘钥来生成签名,生成的签名sign也是需要作为一个参数在接口中传入。 每个Appid会分配一个秘钥,这个秘钥是保密不公开的提供给用户。
4)、签名的生成会按照时间戳+appid,然后使用秘钥来生成签名。
5)、每次请求返回(不管实时还是离线),都会返回一个唯一的requestID给用户。用户可以用这个requestID来调用查询接口查询已经实时合成过的banner图,也可以查询离线合成的banner图。
2、在离线请求中,如果用户传入了回调的url地址,那么在离线处理完后,我们会自动进行回调,在设计时,我们特别做了考虑。
3、kafka也可以作为一个入口,比如大量的合成,用户可以直接推入到kafka中,因为通过http请求进行离线合成,还是会有非常大的请求消耗。
4、在架构图中,我们设计了
Iwogh-service:主要做接口API服务,不涉及逻辑处理,接收到的离线合成是,直接把请求放入到kafka中。
Iwogh-pps-web:用户工作台模块,包括智能合成和手动合成
Iwogh-web:后台管理模块,在第二轮迭代中,我们把工作台和后台管理进行了拆分,拆成了两个web服务,作为两个war包
Iwogh-offline-merge:负责离线合成处理,负责消费kafka中的离线请求数据,并且去调用算法服务处理,处理完的结果放入到新的kafka中。
Iwogh-online-merge:负责处理实时请求服务,去调用算法处理。并且负责工作台过来的banner图处理请求。处理完成的请求,统一发送到kafka中。
Iwogh-data-process:消费处理完成的kafka结果数据,负责结果数据的统一入库处理,以及离线请求的回调处理。
由于我们存储了所有的处理请求和结果,在这里,我们不是选用的mysql来存储这些数据,而是hbase,hbase很适用于我们的场景,由于requestId永远是唯一的,所以hbase的rowkey可以用requestId就可以了。
而且hbase支持batch查询,也就是一次可以传入多个requestId来进行查询,效率也是非常高。
5、我们使用springcloud中的Zuul来作为我们的接口服务请求中的sign签名认证校验,Zuul非常适合这种场景。
未完待续
您可能感兴趣的文章
- 一个硅谷创业者的困惑:拿到VC投资,走上失败循环?
- 百度App完成双引擎双生态布局
- 谷歌搜索算法更新:对播客内容推出垂直推荐功能
- 百度App完成双引擎双生态布局
- 短视频如何运营?
- 日本版的今日头条,成了第一家媒体独角兽
- 字节的搜索,难跳动
- 抖音上的淘客,是怎么玩的?
未经允许不得转载:杂烩网 » 苏宁人工智能研发中心智能创意平台架构成长之路(一)–长篇开篇



